3.3: Coupon Recommendation
Most of the features in this dataset
are categorical or ordinal. The dependent variable in this dataset is binary
1|0, as the nature of the problem is classification. We created another column
to represent the dependent variable couponstatus
with descriptive values accepted
and not accepted for ease of
understanding. We explored the relationship between different classes of the
dependent variable and different categories of features. Crosstab function in
pandas library are used for inspecting the association of different classes
with different categories.
During our investigation, we found
that different categories within the same feature inclined against different
classes to a noticeable extent. These features are 'weather', 'coupon', 'maritalStatus', 'occupation', and 'CoffeeHouse'.
Let s observe each of these features one by one and seek answers to 3 What
questions.
Question 1: What do the patterns in this visualization say?

Table 3.3.1: Crosstab
of couponstatus with weather
For the weather feature, more people accept the coupon if it is sunny
weather. Let s now explore the relationship between the type of coupon and its
acceptance in table 3.3.2 below.
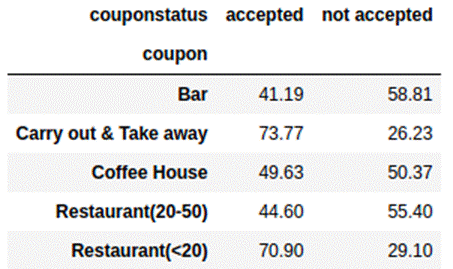
Table 3.3.2: crosstab of couponstatus with the type of coupon
offered in the coupon feature
More people accept coupons if it is
a coupon for Carry out & Take away or if it is a restaurant coupon of
value less than $20. Ironically, fewer people accepted a higher-value
restaurant coupon which is between $20-$50. Let s now explore the relationship
between marital status and the acceptance rate of coupons in table 3.3.3 below.
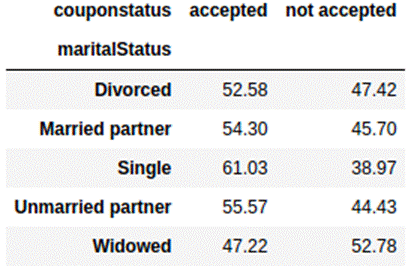
Table 3.3.3: crosstab of couponstatus with the marital status
Everyone, except widowed individuals
accepted more coupons than they rejected. Single people have the highest
likelihood of accepting coupons against other groups. Let s explore the
relationship between different occupations and the likelihood of accepting
coupons in table 3.3.4 below.
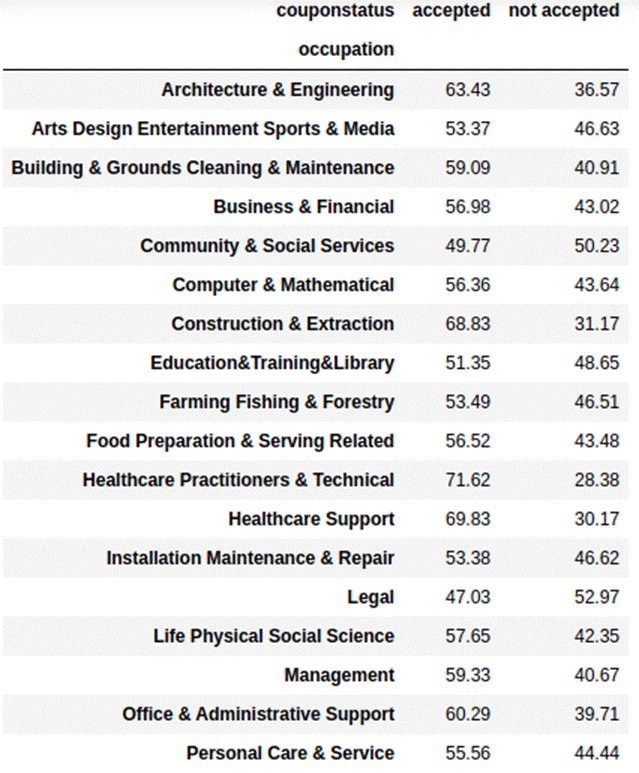

Table 3.3.4: crosstab of couponstatus with the type of
occupation of person
People who work in architecture and
construction related professions, healthcare-related professions, as well as
production occupations accepted coupons more often. However, people who are
retired, work in the legal profession, or work for the community and social
services more often did not accept coupons.
Let us look at the combined effect
of all these features through a correspondence analysis plot and try to answer
the second question.

Figure 3.3.1: Correspondence
analysis of features with coupon acceptance.
Question 2: So, what does this pattern say about my problem
statement and how it can affect my problem statement?
We used multiple features together
in figure 3.3.1 for correspondence analysis. We will zoom into different
quadrants to understand the plot better. The bottom left and top right
quadrants have the coupon accepted and not accepted values respectively.
Let us look at figures 3.3.2 and 3.3.3 respectively to understand each of these
quadrants.

Figure 3.3.2: Bottom left quadrant
of correspondence analysis with couponstatus_accepted.

Figure 3.3.3: Top right quadrant of
correspondence analysis with couponstatus_not
accepted.
We can use correspondence analysis,
by looking at figure 3.3.2, from the proximity of people who accepted coupons
with attributes to make judgments about patterns in the data. People who
accepted coupons were mostly those who were offered to carry out & takeaway
coupons. Restaurant coupons of value less than $20 were also accepted. When the
weather was sunny, more people accepted coupons. Those who visit coffee houses
either 1-3 times or more than 8 times a month also accepted more coupons than
rejected. People who identified their profession as business & financial
accepted more coupons than rejected.
Similarly, from figure 3.3.3, by
looking at the proximity of people who did not accept coupons, we can see that
people who work at community & social services or protective services,
people to whom either bar coupons were given or restaurant coupons of $20-$50
value and people who never went to the coffee house were most likely to not
accept the coupon. People also did not accept coupons when the weather was
rainy or snowy. All of these patterns match with descriptive statistics, except
for people who work for protective services, for whom only 35.43% of people did
not accept and the rest of the majority accepted coupons.
If we can somehow include the
patterns we discovered through EDA as features in our model, we might be able
to get better performance. For this, let's find the answer to question 3.
Question 3: Now what should I do to inculcate the patterns
discovered during EDA? Should I include this information as a new feature or
should I perform data cleaning?
We created 2 features based on
combined information from correspondence analysis and descriptive statistics. accepted_coupon feature has a binary
coded 1|0 value, based on information from correspondence analysis.
The second feature rejected_coupon has a 1|0 value, based
on the proximity of attributes for people who did not accept coupons in the
correspondence analysis plot, except for people who work for protective
services, as it contradicted descriptive statistics.
For these 2 created features, we
performed a chi-square test to validate the relationship between each created
feature and the dependent variable. We found that the p-value of the test in
both cases was below 0.05, which proved the validity of the relationship and
the usefulness of the created features.