6.5: Putting Everything Together
We tried all the methods discussed
in this chapter for the 4 datasets. In this section, we will look at the best
results achieved for each dataset.
Certain feature selection methods
are computationally expensive, whereas some others are computationally
prohibitive. Backward and step feature selection methods in sequential feature
selection are of computationally prohibitive type. We tried executing these
methods in an intel i7, 64GB RAM machine. For linear and Xgboost models, many
times its execution wasn't completed even after 48 hours. At this point, we
stopped the Jupyter notebook cell and moved on to the next method. This
criterion was applied to all methods where it took more than 48 hours, it was
stopped.
6.5.1 Hotel Total
Room Booking
We tried different models and
feature selection methods. Of all the methods, Xgboost regression, when used
with the filter method, gave the best performance. For cross-validation test,
and validation data, the RMSE was observed to be 13.9. RMSE for the external
test data was identified as 5.9. The detailed results for each cross-validation
can be seen in figure 6.5.1.
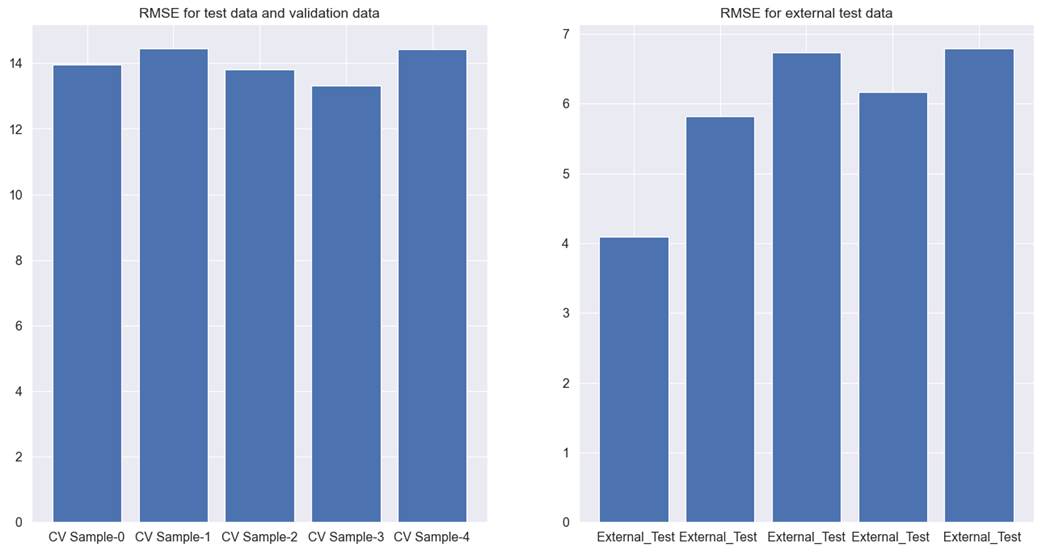
Figure 6.5.1 performance of Xgboost
tree model with filter method for feature selection on cross-validation test,
validation, and external test data for hotel total room booking prediction
The results came as an improvement
upon the results reported in chapter 5. It still has a few areas for
improvement. Firstly, the difference in results between the two test data sets
is quite high. Also, among different cross-validations, the results are not
consistent and fluctuate drastically. This can be seen by comparing the first
vs third cross-validation results for external test data. Secondly, the results
despite being better than what was reported in chapter 5, still fall short and
RMSE are quite high. We will need to try other feature selection methods to see
if the results are any different.
6.5.2 Hotel Booking
Cancellation
We tried different models and
feature selection methods. Of all the methods, the Xgboost classifier, when
used with the filter method, gave the best performance. For the
cross-validation test, and the validation data precision was recorded at 0.835,
and 0.877 for external test data. The detailed results for each
cross-validation can be seen in figure 6.5.2.
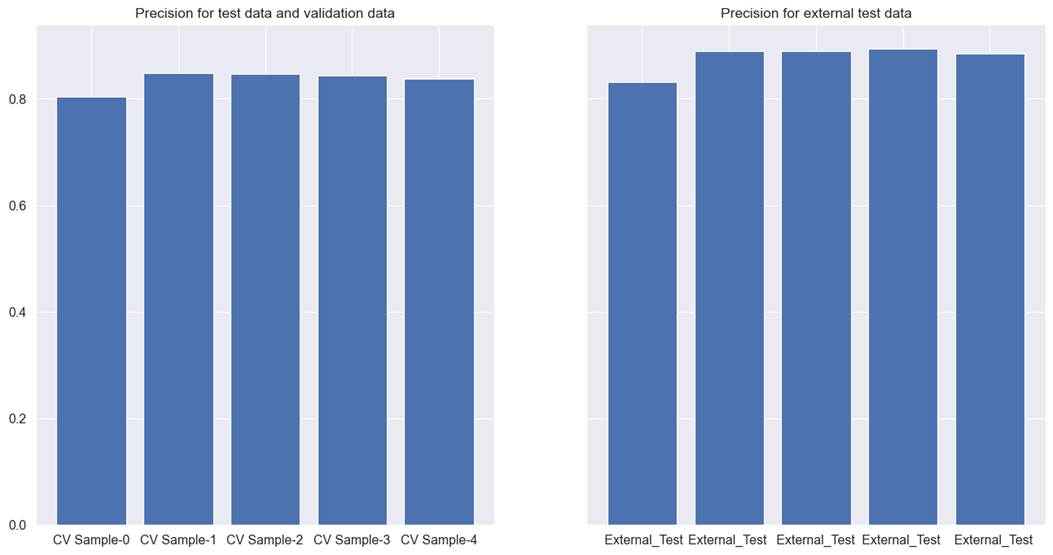
Figure 6.5.2 performance of Xgboost
tree model with filter method for feature selection on cross-validation test,
validation, and external test data for hotel booking cancellation prediction
The previous results achieved in
chapter 5 were better than the results obtained through the filter method.
However, recall improved to a slight extent, in comparison to previous results.
Even then, we still need to improve on both the precision and recall for both
datasets. Also, we need to bring the performance of both datasets to a similar
level. Finally, the results in the 1st cross-validation is poor than the rest
of the cross-validations. All these points suggest us to try other methods of
feature selection to find a better solution.
6.5.3 Car Sales
We tried different models and
feature selection methods. Lightgbm regression, when used with the filter
method, gave the best performance of all the methods. For cross-validation
test, and validation data RMSE was observed to be 398263, and 230356 for
external test data. The detailed results for each cross-validation can be seen
in figure 6.5.3.
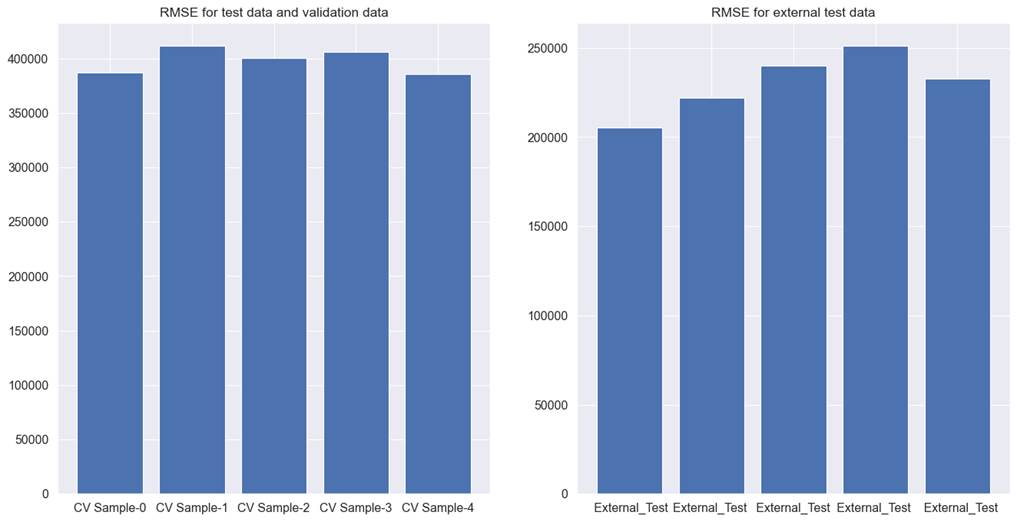
Figure 6.5.3 performance of Lightgbm
tree model with filter method for feature selection on cross-validation test,
validation, and external test data for used car price prediction.
The results obtained through the
filter method are marginally better than the previous results presented in
chapter 5. Even then, it suffers from the same issues we saw in chapter 5.
Results across different test datasets are inconsistent. Results across
different cross-validations are not consistent. If we had to use this model, we
cannot say with confidence that it will generalize well on new unseen data, to
the extent it does for the test, validation, and external test data. Also, the
RMSE values for car prices are very high to be considered acceptable.
As the results presented for car
prices are not acceptable enough to be used as a model, we will try other
methods of feature selection in subsequent chapters.
6.5.4 Coupon Recommendation
We tried different models and
feature selection methods. Of all the methods, the Xgboost classifier, when
used with the filter method, gave the best performance. For the
cross-validation test, validation data precision was recorded at 0.708, and
0.755 for external test data. Although recall worsened than previous results to
a small extent. The detailed results for each cross-validation for precision
can be seen in figure 6.5.4 below.
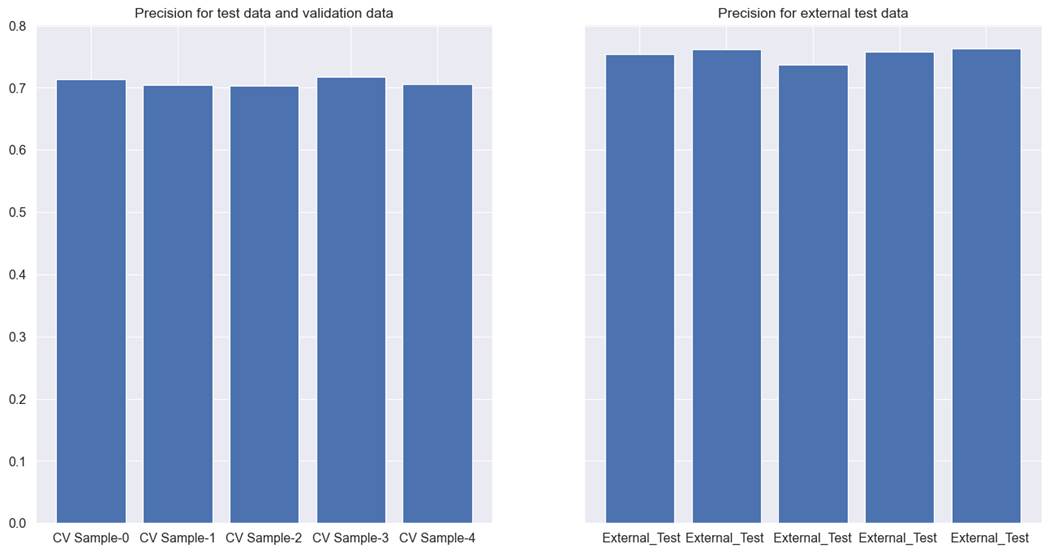
Figure 6.5.4 performance of Xgboost
tree model with filter method for feature selection on cross-validation test,
validation, and external test data for coupon recommendation dataset.
This model, like its predecessor model discussed in chapter
5 suffers from the same issues. The precision and recall are not good enough
and the results in external test data are not consistent with cross-validations
test and validation data. We will try other methods of feature selection in the
next chapters to see if any improvement is possible.