8.6: Putting Everything Together
For certain models, such as Xgboost
and linear models, we have used GPU for training the model. For Lightgbm, we
have used a 64GB RAM machine to compute faster.
These algorithms provide the best
possible combination of features. These are not necessarily the best and ideal
combination of features. As the result, there might still be opportunity for
improvement. If we use the feature set generated by a metaheuristic algorithm,
and perform feature selection again, there might be chance for even better
performance. We will see this for hotel total room booking prediction modeling,
where we perform genetic algorithm multiple times. In each new iteration of
genetic algorithm, we use output set of features from previous iteration of
genetic algorithm. In each iteration we try to get better performance than the
previous iteration.
8.6.1 Hotel Total
Room Booking
We used all 4 metaheuristic
algorithms with the 3 models. Amongst all, Lightgbm and genetic algorithm
performed the best. While it performed best, there might still be a chance of
improving the feature combination. We used the list of features obtained from
the genetic algorithm as input features and performed the genetic algorithm a
few more times to refine the feature list even further. We performed this
exercise a total of 5 times and saw improvement for the 2nd, 3rd, and 4th
iterations. Beyond 4th iteration, there was no more improvement.
For the genetic algorithm, we used a
population of 75 and executed 25 generations for the first iteration. For
subsequent iterations, the number of generations was reduced to 20. Output from
the iteration of the genetic algorithm was used as input for the next generation
of feature selection. At each iteration of the genetic algorithm, execution
time was limited to 1200 minutes.
At 1st iteration, the number of
features from the genetic algorithm was 44. At the 2nd, 3rd, and 4th
iterations, the number of features reduced from 44 to 20, 10, and 9
respectively. Also, at the 4th iteration, RMSE was reduced to 8.63 for test and
validation datasets. RMSE for external test data also decreased to 8.79.
Results from each cross-validation are presented in figure 8.6.1.

Figure 8.6.1 performance of Lightgbm
tree model with genetic algorithm feature selection on cross-validation test,
validation, and external test data for hotel total room booking prediction
This is the best result found so far
for the hotel total rooms prediction dataset. RMSE of error is both the test
datasets are very similar, and there is little to no difference in results
across different cross-validations. Both of these factors suggest that the
model will generalize well on unseen data.
8.6.2 Hotel Booking
Cancellation
Xgboost and simulated annealing
performed the best for the hotel booking cancellation dataset. It has 0.88 as
precision for cross-validation test and validation dataset. For the external
dataset, precision was noted as 0.93. This solution did have a downside with a
low recall at 0.41 for the external test data. For simulated annealing, we used
35 iterations and 75 perturbs for performing feature selection. Figure 8.6.2.1
explains the model performance for each cross-validation.
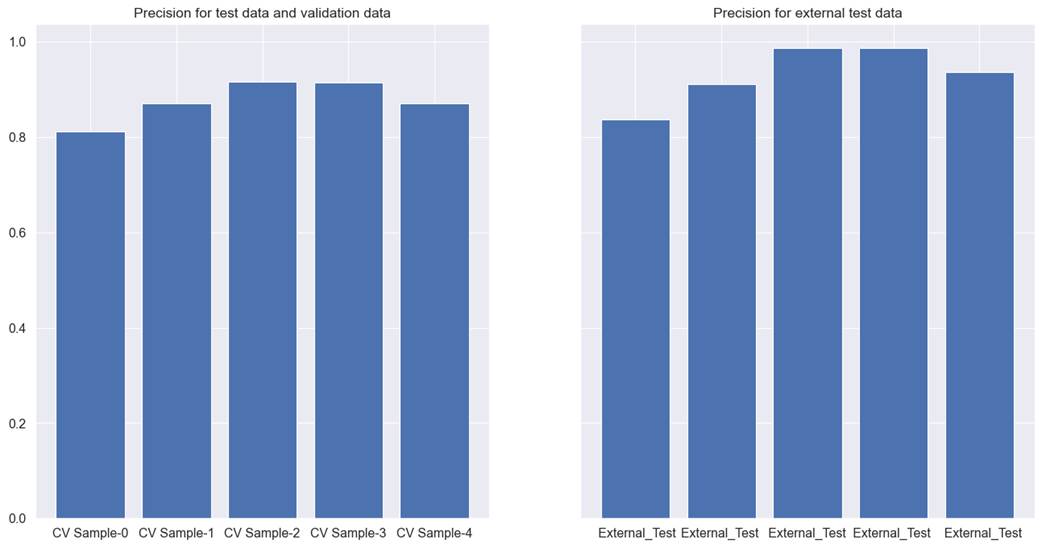
Figure 8.6.2.1 performance of
Xgboost tree model with simulated annealing feature selection on
cross-validation test, validation, and external test data for hotel booking
cancellation
There is another solution which is
the combination of Xgboost and genetic algorithm, and it performed as second
best. It has 0.86 as precision for cross-validation test and validation
dataset. For the external dataset, precision was noted as 0.92. This solution
has a relatively better recall at 0.41 for the external test data. We used 20
generations for 75 chromosomes for the algorithm execution. Figure 8.6.2.2
explains the model performance for each cross-validation.
Both the solutions, especially the
first solution is not perfect, but nearly useful. If the precision can be
reliably said to be above 0.9 and close to 0.95, the hotel can use the
predictions from the model for overselling the rooms. Even though the model has
a lower recall. To overcome this, we can try an ensemble of two or more models
to see its impact on precision and recall. Imagine a model that can predict
hotel booking cancellations with a high degree of reliability. Even if it can
identify only 40 percent of cancellations and cannot identify the rest of the
60 percent of the cancellations, it will still be useful for the hotel to
minimize loss occurring because of 40% of cancellations.
Comparing the solutions obtained
through all 4 metaheuristics algorithms, these are the best result achieved for
this dataset, in comparison to other feature selection methods.

Figure 8.6.2.2 performance of
Xgboost tree model with genetic algorithm feature selection on cross-validation
test, validation, and external test data for hotel booking cancellation
8.6.3 Car Sales
We tried different combinations of
metaheuristics algorithms and models. The best performance was achieved by the
combination of Lightgbm and simulated annealing. For cross-validation test and
validation data, RMSE was 197495, whereas for the external test data it is
224034. It is better than the results reported in chapter 7. For simulated
annealing, we used 35 iterations with 75 perturbations.
Figure 8.6.3 shows the model
performance across different cross-validations. RMSE is not very consistent
across all cross-validations. RMSE is different across different test datasets.
However, the major issue in this dataset is that RMSE is still very high. For
this dataset, none of the feature engineering and feature selection helped us
achieve a workable model that can predict the price of used cars reliably. This
indicates that the dataset requires data cleaning and domain-specific feature
engineering. Domain knowledge in particular can help in organizing data that
can be easier for the model to learn, finding anomalies, and treating it to
ensure a dataset with the least amount of noise, and finally in creating
features that permeate from domain knowledge.
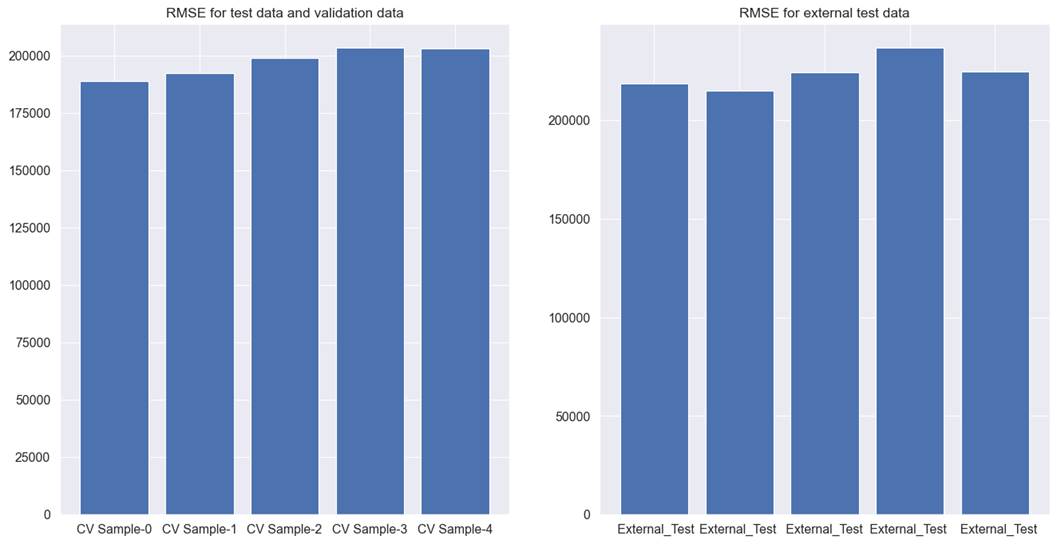
Figure 8.6.3 performance of the
Lightgbm model with simulated annealing feature selection on cross-validation
test, validation, and external test data for used car price prediction.
8.6.4 Coupon
Recommendation
For this dataset, Xgboost performed
the best with simulated annealing feature selection. It has 0.78 as precision
for cross-validation test and validation dataset. For the external dataset,
precision was noted as 0.79. This solution did have a downside with a low
recall at 0.59 for the external test data. For simulated annealing, we used 35
iterations and 75 perturbs for performing feature selection. Figure 8.6.4
explains the model performance for each cross-validation.
This is the best performance that
could be achieved for the dataset, across all feature selection methods and
model techniques. However, these results are not good enough to be accepted as
a reliable model. If either the precision or recall could have been close to
0.9 or higher, we could have obtained a reliable model. Hence, although model
performance across different cross-validations is very similar, and there is a
very small difference between the two different test datasets, we will discard
this model.
In the absence of domain knowledge
for this dataset, we at this point halt any further effort to improve the model
for this dataset.
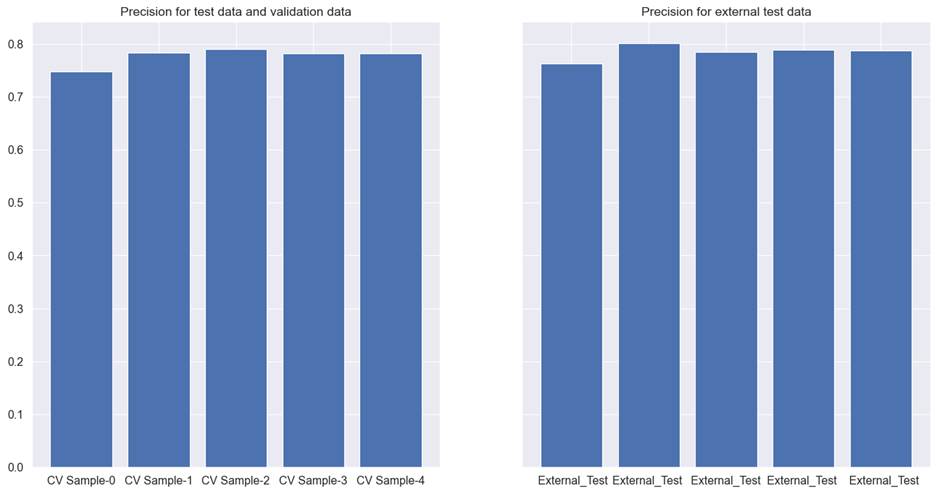
Figure 8.6.4 performance of the Xgboost model with simulated
annealing feature selection on cross-validation test, validation, and external
test data for coupon recommendation prediction.